
2.1. Storing object data
bulk로 넣는 File 형식일 때
Google Cloud Storage
타 cloud storages이 제공하는 대부분의 특성을 가짐
1) Off-site management
2) Quick implementation
3) Cost-effective
4) Scalability
5) Business continuity
2.2. Storing database data
RDBMS와 NoSQL같은 DB 저장 시
Relational (RDBMS)
- Google Cloud SQL (MySQL, PostgreSQL)
- Spanner (Horizontally scalable)
- 기존 ecosystem (Microsoft SQL Server)
Non-relational (NoSQL)
- Google Bigtable(wide-column)
- Firestore (Flexible, scalable)
- 기존 ecosystem (MongoDB, Cassandra)
2.3. Storing data warehouse data
분석용도로 DW에 큰 data 저장 시
BigQuery
managed DW
Feature
a fully-managed, serverless data warehouse that enables scalable analysis over petabytes of data.
- serverless cloud 서비스로 설치/운영이 필요없음 (NoOps)
- RDBMS의 SQL 사용 (ANSI)
- speed (in-memory BI Engine and machine learning built in)
- handling big data supported by cloud scale infra
- save 3 replication (data loss risk X)
-
batch / streaming
- easier than Hadoop, Spark: install, configure env, develop MapReduce logic…
prerequisite:
create Google Cloud project
enable the BigQuery API
create a service account (key)
permissions to open the BigQuery Geo Viz
permissions to open the Bucket1
Interface
1) Web UI
Query를 WEB UI 상으로 실행
3) Command-Line
Shell 사용해서 실행
bq mk dataset
3) REST API
Java나 Python 프로그래밍으로 구현 HTTP 실행
from google.cloud import bigquery
client = bigquery.Client()
4) Geospatial analytics
Query를 WEB UI 상으로 실행해서 지도에서 표시
example
1) table
CREATE OR REPLACE TABLE ecommerce.revenue_transactions_20170801
#schema
(
fullVisitorId STRING NOT NULL OPTIONS(description="Unique visitor ID"),
visitId STRING NOT NULL OPTIONS(description="ID of the session, not unique across all users"),
channelGrouping STRING NOT NULL OPTIONS(description="Channel e.g. Direct, Organic, Referral..."),
totalTransactionRevenue FLOAT64 NOT NULL OPTIONS(description="Revenue for the transaction")
)
OPTIONS(
description="Revenue transactions for 08/01/2017"
) AS
SELECT DISTINCT
fullVisitorId,
CAST(visitId AS STRING) AS visitId,
channelGrouping,
totalTransactionRevenue / 1000000 AS totalTransactionRevenue
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE date = '20170801'
AND totalTransactionRevenue IS NOT NULL #XX transactions
;
2) view
CREATE OR REPLACE VIEW ecommerce.vw_large_transactions
OPTIONS(
description="large transactions for review",
labels=[('org_unit','loss_prevention')],
expiration_timestamp=TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL 90 DAY) # 90일 이내 생성된 뷰 조회
)
AS
#standardSQL
SELECT DISTINCT
SESSION_USER() AS viewer_ldap,
REGEXP_EXTRACT(SESSION_USER(), r'@(.+)') AS domain,
date,
fullVisitorId,
visitId,
channelGrouping,
totalTransactionRevenue / 1000000 AS totalTransactionRevenue,
currencyCode,
STRING_AGG(DISTINCT v2ProductName ORDER BY v2ProductName LIMIT 10) AS products_ordered
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE
(totalTransactionRevenue / 1000000) > 1000
AND currencyCode = 'USD'
AND REGEXP_EXTRACT(SESSION_USER(), r'@(.+)') IN ('google.com') # session user가 google.com 인 경우만 조회 가능
GROUP BY 1,2,3,4,5,6,7,8
ORDER BY date DESC # latest transactions
LIMIT 10;
session user 정보 조회
SELECT
SESSION_USER() AS viewer_ldap;
3) partitioned table
CREATE OR REPLACE TABLE ecommerce.partition_by_day
PARTITION BY date_formatted
OPTIONS(
description="a table partitioned by date"
) AS
SELECT DISTINCT
PARSE_DATE("%Y%m%d", date) AS date_formatted,
fullvisitorId
FROM `data-to-insights.ecommerce.all_sessions_raw`
partition expiration 되게 하면
CREATE OR REPLACE TABLE ecommerce.days_with_rain
PARTITION BY date
OPTIONS (
partition_expiration_days=60, # 60일 이후에 expire됨
description="weather stations with precipitation, partitioned by day"
) AS
SELECT
DATE(CAST(year AS INT64), CAST(mo AS INT64), CAST(da AS INT64)) AS date,
(SELECT ANY_VALUE(name) FROM `bigquery-public-data.noaa_gsod.stations` AS stations
WHERE stations.usaf = stn) AS station_name, -- Stations may have multiple names
prcp
FROM `bigquery-public-data.noaa_gsod.gsod*` AS weather
WHERE prcp < 99.9 -- Filter unknown values
AND prcp > 0 -- Filter
AND CAST(_TABLE_SUFFIX AS int64) >= 2018
4) full outer join
SELECT DISTINCT
website.productSKU AS website_SKU,
inventory.SKU AS inventory_SKU
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
FULL JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
WHERE website.productSKU IS NULL OR inventory.SKU IS NULL
5) cross join
CREATE OR REPLACE TABLE ecommerce.site_wide_promotion AS
SELECT .05 AS discount; -- discount율 명시 테이블 만들고
INSERT INTO ecommerce.site_wide_promotion (discount)
VALUES (.04),
(.03); -- discount율 추가
SELECT DISTINCT
productSKU,
v2ProductCategory,
discount
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
CROSS JOIN ecommerce.site_wide_promotion
WHERE v2ProductCategory LIKE '%Clearance%' -- 각 물품별 .05,.04,.03 3가지 할인율로 나옴 (x3)
6) duplication 제거
#standardSQL
# take the one name associated with a SKU
WITH product_query AS (
SELECT
DISTINCT
v2ProductName,
productSKU
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE v2ProductName IS NOT NULL
)
SELECT k.* FROM (
# aggregate the products into an array and
# only take 1 result
SELECT ARRAY_AGG(x LIMIT 1)[OFFSET(0)] k -- 1 row (0번째)만 가져오겠다
FROM product_query x
GROUP BY productSKU # unique 해야하는 데이터
);
Working with arrays
#standardSQL
# how can we find the products with more than 1 sku?
SELECT
DISTINCT
COUNT(DISTINCT productSKU) AS SKU_count,
STRING_AGG(DISTINCT productSKU LIMIT 5) AS SKU,
v2ProductName
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE productSKU IS NOT NULL
GROUP BY v2ProductName
HAVING SKU_count > 1
ORDER BY SKU_count DESC
# product name is not unique (expected for variants)
for reducing the price
1) query 하기 전에 preview 사용 (비용 X)
2) 사전에 query result size 체크 (오른쪽 display)
3) maximum billing limit 설정
4) prevent asterisk(*): column oriented storage로 wild card 사용시 column마다 압축 풀어서 가져와야 함
5) partition table 및 clustered index table 사용: random access 줄어듦
6) array 형 사용
7) 적절한 슬롯2 수 사용 ( on-demand / flat-rate pricing )
Cloud Data Fusion
Data pipeline 구축 및 관리 (fully-managed)
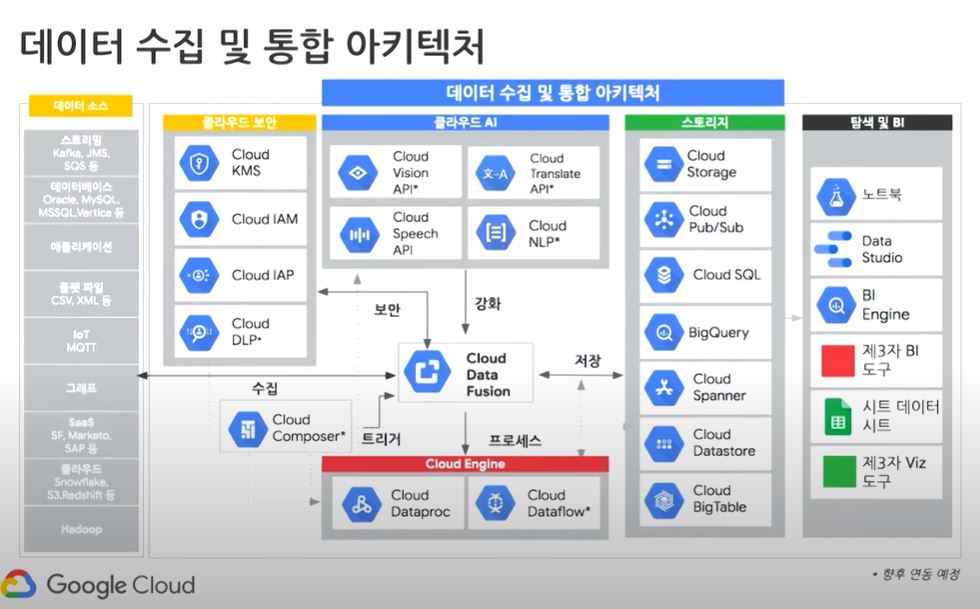
1) Pipelines create complex data processing workflows (both batch and realtime) using an intuitive UI (Directed Acylic Graph, DAG)
2) Wrangler
connect to data, and transform it using point-and-click transformation steps
view, explore, and transform a small sample (10 MB) of your data in one place before running the logic on the entire dataset in the Pipeline Studio
3) Metadata
how datasets and programs are related to each other,
full visibility into the impact of changes
4) Hub distribute reusable applications, data, and code to all users in their organization
Wrangler
1) create bucket
export BUCKET=$GOOGLE_CLOUD_PROJECT
gsutil mb gs://$BUCKET
2) data copy to bucker
gsutil cp gs://cloud-training/OCBL163/titanic.csv gs://$BUCKET
3) Wangler로 preprocessing 작업 Google Cloud Storage에 있는 titanic raw가 있는 data 탭으로 가서 먼저 csv parsing을 함
Preprocessing (CLI)
drop :body # 기존 body(:은 컬럼임) 날리기
fill-null-or-empty :Cabin 'none' # Cabin 결측치 처리
send-to-error empty(Age) # Age empty면 에러 처리
parse-as-csv :Name ',' false # Name 컬럼 콤마 기준으로 컬럼을 두개로 나눔
drop Name
fill-null-or-empty :Name_2 'none'
rename Name_1 Last_Name
rename Name_2 First_Name
set-type :PassengerId integer
parse-as-csv :First_Name '.' false
drop First_Name
drop First_Name_3
rename First_Name_1 Salutation
fill-null-or-empty :First_Name_2 'none'
rename First_Name_2 First_Name
send-to-error !dq:isNumber(Age) || !dq:isInteger(Age) || (Age == 0 || Age > 125)
set-type :Age integer
set-type :Fare double
set-column Today_Fare (Fare * 23.4058)+1
generate-uuid id
mask-shuffle First_Name
more에 가서 view schema 하면 해당 데이터 meta 정보 json으로 추출 가능
Transformation steps 탭에 있는 다운로드 아이콘 누르면 preprocessing 내역 추출 가능
4) insight 탭으로 가서 columns별 데이터 distribution 시각화 된 것 확인

Pipelines Studio 내 Wrangler로 작업한 노드의 Properties에 들어가면, Wrangler로 한 작업들의 명세를 확인할 수 있음
Pipelines
1) target인 BigQuery에 dataset 미리 생성 (demo_cdf)
2) Data Fusion에서 create pipeline (Batch) 눌러서 Studio 이동
3) Sink 섹션에 있는 BigQuery를 배치해서 pipeline 연결하고 Properties 구성 (dataset: demo_cdf)
4) save 후 deploy 하고, run
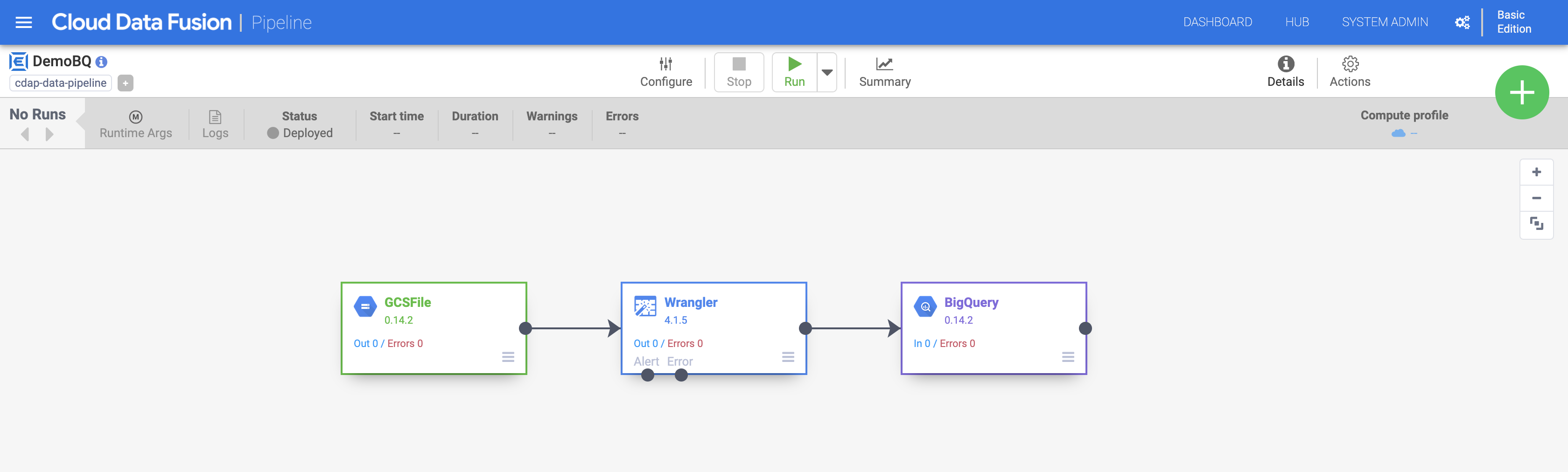 5) summary에서 해당 job의 dash board 확인 가능
5) summary에서 해당 job의 dash board 확인 가능