- 1. Spark 개요
- 2. Spark Architecture
- 3. PySpark
📎 Spark User Guide, Spark The Definitive Guide
1. Spark 개요
Unified Computing Engine and a Set of Libraries for Parallel Data Processing on Computer Clusters
대량 데이터 처리를 위한 클러스터 자원으로 데이터를 분산 병렬 처리
1.1. Spark 주요 용도
- Spark SQL (Batch processing): big & complex, processing massive data, higher latencies
- Spark Streaming (Real time analytics): relatively simple and generally independent, one at a time processing, sub-second latency
- MLlib (Machine learning)
- GraphX (Graph processing)
spark streaming의 경우 개발하기는 어렵지 않으나, 운영(debugging)이 어려움
1.2. Hadoop vs Spark
Hadoop의 MPP1 (Massive Parallel Processing)을 기반으로 자원 대용량 처리하고
기존 Hadoop의 MapReduce에서 disk I/O 부하가 심했던 부분을 memory에서 빠르게 작업
- RDD -> DataFrame -> SQL 데이터 처리 추상화
- DAG 기반의 실행 최적화
- In-memory write으로 Map Reduce 작업을 최적화
1.3. RDD (Resilient Distributed Datasets)
Immutable distributed collection of your data, partitioned across nodes in your cluster
- 분산 병렬 처리를 위한 데이터를 추상화
- Immutable 데이터 집합
- 클러스터 내의 서로 다른 노드에 저장하고 읽음
RDD vs DF vs DataSet(SQL)
| RDD | Data Frame | DataSet | |
| Release | 1.0 |
1.3 |
1.6 |
| Data Representation | Java나 Scala object | column의 이름이 있는 organized된 분산 컬렉션. RDB 테이블과 유사 | Data Frame의 확장. type-safe, oop interface 제공, Catalyst query optimizer 의 성능 이점, off heap storage 메커니즘 제공 |
| Data Format | 비정형/정형데이터의 쉽고 효율적인 처리. Data Frame과 DataSet처럼 스키마를 유추하지 않음 | 비정형/반정형 데이터에서만 동작. column name을 가진 형태로 Spark가 스키마를 관리 | DataFrame과 같이 정형/반정형 데이터의 쉽고 효율적인 처리. row의 JVM object 형태나 row object collection 형태로 표현. encoder를 통해 테이블 형태로 표현 |
| Data Source API | 어떤 데이터소스든 사용가능 | AVRO, CSV, TSV, JSON, HDFS, HIVE Table, RDB 등의 데이터 소스가 가능 | 어떤 데이터소스도 가능 |
| immutablility, interoperability |
RDD는 기본적으로 불변. RDD가 표형식일경우 RDD.toDF로 DataFrame으로 변경가능 |
DataFrame으로 변환하고 나면 domain object를 재생성할 수 없음. RDD.toDF를 할경우 원래 형태의 RDD로 돌아올 수 없다는 것 |
DataFrame의 확장버전으로 RDD와 DataFrame을 DataSet로 변환할 수 있음 |
| compile time type safety | 친숙한 OOP 스타일과 compile-time typesafey 제공 | DataFrame에 존재하지 않는 column에 접근하려고 하면 compile-time typesafe를 보장하지 않음. run-time에서만 확인가능 | compile-time safe 지원 |
| Optimization | Optimization engine이 없음. 개발자가 최적화해야 됨 | Catalyst Optimizer가 있음. 이를 이용해서 최적화 진행 | 쿼리 계획 최적화를 위해 DataFrame의 Catalyst optimization이 있음 |
| Serialization | Java Serization 사용 | Off Heap storage를 사용(InMemory)하여 binary format으로. Schema를 알고 있기 때문에 가능. Tungsten 실행 백엔드를 가지고 있어서 메모리를 명시적으로 관리하고 동적으로 bytecode를 만듬 | Encoder가 있기 때문에 Spark 내부의 Tungsten binary format 사용 |
| GC(Garbage Collection) | 각 Object의 생성과 파괴로 인한 GC의 overhead가 있음 | 각 row의 개별 Object를 구성할 때 GC 코스트 방지 | Serialization때문에 GC가 OBject를 파괴할 필요가 없음. off heap data serialization을 사용함 |
| Efficiency / Memory use | Java와 Scala object에서 개별적으로 Serialization을 하면 효율성이 저하됨 | Serialization에 off heap memory를 사용하면 overhead가 줄어듬. |
Serializaed data에 대한 작업을 수행하고 메모리 사용성을 개선할 수 있음 |
| Lazy Evaluation | 기본적으로 lazy Evaluation. Transformation의 경우 이것을 실행했다는 것만 기억하고 Action이 Driver Program에 결과를 보낼 필요가 있을 때만 계산 | Lazy Evaluation. Action이 나타날 때만 동작함 | RDD나 DataFrame과 같음 |
| Language Support | Java, Scala, Python, R | RDD와 같음 | Scala와 Java. Spark 2.1.1 기준 |
| Schema Projection | 명시적으로 사용됨. 스키마 정의가 필요함 | 데이터 소스로부터 스키마를 검색하고 수행함. Hive의 경우 Hive Meta store, DB의 경우 DB Engine. | Spark SQL Engine을 사용하여 자동 탐색 |
| Aggregation | 느림 | 대규모 데이터 셋에 대한 집계 통계를 작성하기 때문에 빠르게 분석함 | 빠름 |
| Use-cases | low-level 작업이 필요하거나 추상화가 필요한 경우에 사용 | high-level 작업이 필요하거나 정형/반정형 등 많은 케이스 | DataFrame과 동일 |
RDD 예시
low level interface, Data Containers
각기 다른 프로세스 요소들을 추상화한 같은 형태
# Hadoop에서 읽은 RDD
path = hdfs://...
# Filtered된 RDD
func = contains(...)
# Mapped된 RDD
func = split(...)
Fault되면 Loss된 데이터 이전부터 다시 계산
data = sc.textFile(...).split("\t")
data.map(lambda x: (x[0], [int(x[1]), 1]))
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]])
.map(lambda x: [x[0], x[1][0] / x[1][1]])
.collect()
DataFrame 예시
코드가 직관적이고 schema를 가지는 interface
sqlCtx.table("people")
.groupBy("name")
.agg("name", avg("age"))
.collect()
DataSet 예시
SQL로 수행 가능
SELECT name, avg(age)
FROM people
GROUP BY name
2. Spark Architecture
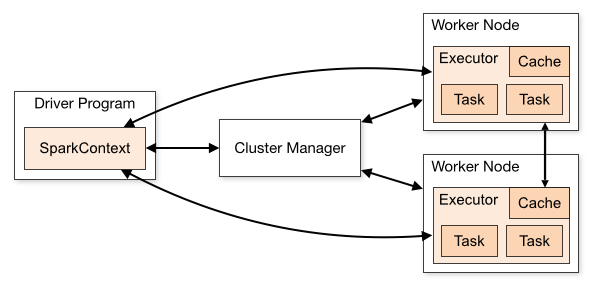
executor 개수와 resource 할당
2.1. Cluster Manager
worker와 executors 사이에 자원을 중계해주는 역할
resource를 효율적으로 분배
ex) Spark StandAlone(cluster X), (Hadoop)Yarn, Mesos, Kubernetes
2.2. Driver Process
SparkContext를 생성하고 RDD를 만들고 operation을 실행하는 프로세스
Spark-submit을 하면,
Spark Driver가 Cluster Manager로부터 Executor 실행을 위한 리소스를 요청
Spark Context는 작업 내용을 task 단위로 분할하여 Executor로 보냄
2.3. Executors
주어진 작업의 개별 task들을 실행하는 작업 실행하고 결과 return
1) 애플리케이션을 구성하는 작업들을 실행하여 driver에 그 결과를 return
2) 각 executor 안에 존재하는 block manager라는 서비스를 통해 사용자 프로그램에서 캐시하는 RDD를 저장하기 위한 메모리 저장소를 제공
Python,R Process <-> JVM(Spark session) -> Executors
End to End: csv file read(narrow) -> DataFrame sort(wide) -> Array
Operations
1) Transformations: map, filter, groupBy, join lazy operation으로 즉시 실행하는 단계가 아님
2) Actions: count, collect, save 실제로 실행후 driver로 결과 return
Variables
- Accumulator: aggregate multiple values as it progresses
- Broadcast: large read-only variable shared across tasks, operations, large lookup tables
디버깅이나 검증용으로 쓰고, 스파크 스트리밍에서는 accumulator, broadcast 지양 (GC문제..)
2.4. Scheduling
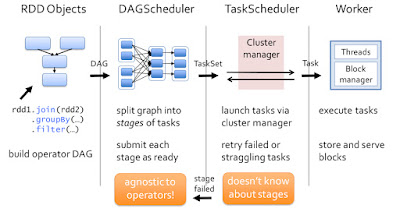
DAG (Directed Acyclic Graphs) Scheduler
3. PySpark
Pandas vs PySpark
Pandas:
단일 서버 memory로만 처리
numpy의 ndarray 기반으로 2차원 데이터 분석용
PySpark:
병렬 CPU로 처리
SQL 연산 지원
select gender from tab
-> spark_df.select(‘gender’)
select * from tab where gender = ‘F’
-> spark_df.filter(spark_df[‘gender’] == ‘F’)
update set age=age + 10 from tab
-> spark_df.withColumns(‘age’, col(‘age’)+10)
select gender, count(*) from tab group by gender
-> spark_df.groupBy(‘gender’).count()
immutable하게 df.drop(‘col1’) 시에 새로운 df 반환 (inplace 옵션 없음)
컬럼 지정 혹은 리스트 출력 시 대괄호 연산자 [] 사용 X
3.1. Creating the spark session and context
Session 생성
import pandas as pd
from PySpark import SparkContext, SparkConf
from PySpark.sql import SparkSession
# Creating a spark context class
sc = SparkContext()
# Creating a spark session
spark = SparkSession \
.builder \
.appName("Python Spark DataFrames basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
spark
DataBricks에서는 따로 session 생성 안해도 spark치면 떠있는 SparkUI 확인 가능
3.2. Load a data file into a DataFrame
File 읽기
- spark.read.csv
# pyspark_df = pd.read_csv('https://www.kaggle.com/.../titanic_train.csv', header='infer')
# databricks FS에서는 read부터 spark.read_csv 함수 읽지 않으면 FileNotFoundError남
pyspark_df = spark.read.csv('/FileStore/tables/titanic_train.csv', header=True, inferSchema=True)
pyspark_df.head() # pyspark.sql.types.Row 타입으로 리스트 형태로 출력
> Out[17]: Row(PassengerId=1, Survived=0, Pclass=3, Name='Braund, Mr. Owen Harris', Sex='male', Age=22.0, SibSp=1, Parch=0, Ticket='A/5 21171', Fare=7.25, Cabin=None, Embarked='S')
읽은 df 확인
- show
- display
pyspark_df.limit(10).show()
> +-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+
|PassengerId|Survived|Pclass| Name| Sex| Age|SibSp|Parch| Ticket| Fare|Cabin|Embarked|
+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+
| 1| 0| 3|Braund, Mr. Owen ...| male|22.0| 1| 0| A/5 21171| 7.25| null| S|
| 2| 1| 1|Cumings, Mrs. Joh...|female|38.0| 1| 0| PC 17599|71.2833| C85| C|
| 3| 1| 3|Heikkinen, Miss. ...|female|26.0| 0| 0|STON/O2. 3101282| 7.925| null| S|
| 4| 1| 1|Futrelle, Mrs. Ja...|female|35.0| 1| 0| 113803| 53.1| C123| S|
| 5| 0| 3|Allen, Mr. Willia...| male|35.0| 0| 0| 373450| 8.05| null| S|
| 6| 0| 3| Moran, Mr. James| male|null| 0| 0| 330877| 8.4583| null| Q|
| 7| 0| 1|McCarthy, Mr. Tim...| male|54.0| 0| 0| 17463|51.8625| E46| S|
| 8| 0| 3|Palsson, Master. ...| male| 2.0| 3| 1| 349909| 21.075| null| S|
| 9| 1| 3|Johnson, Mrs. Osc...|female|27.0| 0| 2| 347742|11.1333| null| S|
| 10| 1| 2|Nasser, Mrs. Nich...|female|14.0| 1| 0| 237736|30.0708| null| C|
+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+
display(pyspark_df.limit(10))
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.25 | null | S |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Thayer) | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.925 | null | S |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.05 | null | S |
| 6 | 0 | 3 | Moran, Mr. James | male | null | 0 | 0 | 330877 | 8.4583 | null | Q |
| 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S |
| 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.075 | null | S |
| 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | null | S |
| 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | null | C |
3.3. View the data schema of a DataFrame
pandas DF로 변경
- toPandas
pd_df = pyspark_df.select('*').toPandas()
pd_df.head() # 기존 pandas처럼 read
> <class 'pandas.core.frame.DataFrame'>
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 None S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 None S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 None S
5 6 0 3 ... 8.4583 None Q
6 7 0 1 ... 51.8625 E46 S
7 8 0 3 ... 21.0750 None S
8 9 1 3 ... 11.1333 None S
9 10 1 2 ... 30.0708 None C
[10 rows x 12 columns]
spark DF로 변경
- spark.createDataFrame
pd_df = pd.read_csv('https://www.kaggle.com/.../mtcars.csv')
sdf = spark.createDataFrame(pd_df)
Schema 확인
pandas의 info와 같은 함수
- printSchema
pd_df.info()
> RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int32
1 Survived 891 non-null int32
2 Pclass 891 non-null int32
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int32
7 Parch 891 non-null int32
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int32(5), object(5)
sdf.printSchema()
> root
|-- Unnamed: 0: string (nullable = true)
|-- mpg: double (nullable = true)
|-- cyl: long (nullable = true)
|-- disp: double (nullable = true)
|-- hp: long (nullable = true)
|-- drat: double (nullable = true)
|-- wt: double (nullable = true)
|-- qsec: double (nullable = true)
|-- vs: long (nullable = true)
|-- am: long (nullable = true)
|-- gear: long (nullable = true)
|-- carb: long (nullable = true)
3.4. Perform basic data manipulation
Select
- show
sdf.show(5)
> +-----------------+----+---+-----+---+----+-----+-----+---+---+----+----+
| Unnamed: 0| mpg|cyl| disp| hp|drat| wt| qsec| vs| am|gear|carb|
+-----------------+----+---+-----+---+----+-----+-----+---+---+----+----+
| Mazda RX4|21.0| 6|160.0|110| 3.9| 2.62|16.46| 0| 1| 4| 4|
| Mazda RX4 Wag|21.0| 6|160.0|110| 3.9|2.875|17.02| 0| 1| 4| 4|
| Datsun 710|22.8| 4|108.0| 93|3.85| 2.32|18.61| 1| 1| 4| 1|
| Hornet 4 Drive|21.4| 6|258.0|110|3.08|3.215|19.44| 1| 0| 3| 1|
|Hornet Sportabout|18.7| 8|360.0|175|3.15| 3.44|17.02| 0| 0| 3| 2|
+-----------------+----+---+-----+---+----+-----+-----+---+---+----+----+
- filter
sdf.filter(sdf['mpg'] < 18).show(5)
>+-----------+----+---+-----+---+----+----+-----+---+---+----+----+
| Unnamed: 0| mpg|cyl| disp| hp|drat| wt| qsec| vs| am|gear|carb|
+-----------+----+---+-----+---+----+----+-----+---+---+----+----+
| Duster 360|14.3| 8|360.0|245|3.21|3.57|15.84| 0| 0| 3| 4|
| Merc 280C|17.8| 6|167.6|123|3.92|3.44| 18.9| 1| 0| 4| 4|
| Merc 450SE|16.4| 8|275.8|180|3.07|4.07| 17.4| 0| 0| 3| 3|
| Merc 450SL|17.3| 8|275.8|180|3.07|3.73| 17.6| 0| 0| 3| 3|
|Merc 450SLC|15.2| 8|275.8|180|3.07|3.78| 18.0| 0| 0| 3| 3|
+-----------+----+---+-----+---+----+----+-----+---+---+----+----+
Update
- withColumn
sdf.withColumn('wtTon', sdf['wt'] * 0.45).show(5)
>+-----------------+----+---+-----+---+----+-----+-----+---+---+----+----+-------+
| Unnamed: 0| mpg|cyl| disp| hp|drat| wt| qsec| vs| am|gear|carb| wtTon|
+-----------------+----+---+-----+---+----+-----+-----+---+---+----+----+-------+
| Mazda RX4|21.0| 6|160.0|110| 3.9| 2.62|16.46| 0| 1| 4| 4| 1.179|
| Mazda RX4 Wag|21.0| 6|160.0|110| 3.9|2.875|17.02| 0| 1| 4| 4|1.29375|
| Datsun 710|22.8| 4|108.0| 93|3.85| 2.32|18.61| 1| 1| 4| 1| 1.044|
| Hornet 4 Drive|21.4| 6|258.0|110|3.08|3.215|19.44| 1| 0| 3| 1|1.44675|
|Hornet Sportabout|18.7| 8|360.0|175|3.15| 3.44|17.02| 0| 0| 3| 2| 1.548|
+-----------------+----+---+-----+---+----+-----+-----+---+---+----+----+-------+
Case When
- col
- when
- count
- isnan
from pyspark.sql.functions import count, isnan, when, col
sdf.select([count(when(isnan(c) | col(c).isNull(), c)).alias(c) for c in titanic_sdf.columns]).show()
>+-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+
|PassengerId|Survived|Pclass|Name|Sex|Age|SibSp|Parch|Ticket|Fare|Cabin|Embarked|
+-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+
| 0| 0| 0| 0| 0|177| 0| 0| 0| 0| 687| 2|
+-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+
3.5. Aggregate data in a DataFrame
Group by
sdf.groupby(['cyl'])\
.agg({"wt": "AVG"})\
.show(5)
>+---+------------------+
|cyl| avg(wt)|
+---+------------------+
| 6| 3.117142857142857|
| 8|3.9992142857142854|
| 4| 2.285727272727273|
+---+------------------+
-
DW workload를 처리하기 위해 자주 사용 <->SMP (Symmetric Multi processor) ↩